This post is based on a short demo/talk I gave at Vertigo recently.
I have two main goals in this discussion:
- How VS2005 handles WPF projects/apps (showing some Blend / VS2005 gotchas)
- A way to look at the role of XAML in WPF architecture
Petzold books
Charles Petzold’s books have always been a huge help to me in getting all the nitty gritty details in Windows UI technology. I started my Chuck P. habit way back with his Programming Windows book. The Book for Win32 Windows programming. Ok, I do have other books too but this is the one I’d want if I was lost on a desert island alone with a c-compiler…
More recently, Petzold has written authoritative .NET WinForms books and I started to notice a trend. Especially in Programming Microsoft Windows Forms, his .NET 2.0 WinForms book, Petzold really pushes a code-everything-yourself approach as opposed to using any of Visual Studio’s “helpful” tools. His point: if you do not understand the code the various visual designer/code generators in VS create, you really do not know what is going on.
I see this as just another statement of the well-known Weasley’s Law:
Never trust anything that can think for itself
if you can’t see where it keeps its brain!
Arthur Weasley — Harry Potter and The Chamber of Secrets
I’m going to focus this very small discussion on how XAML fits in to the WPF dev process and WPF architecture and point out a few gotchas in the current WPF dev tool set.
The WPF dev process
I’m going to step through building a baby application modeled closely on the sample application Microsoft provides at MSDN in Get Started Using Windows Presentation Foundation but I’m going to walk through it highlighting aspects Petzold points out in his new WPF book Applications = Code + Markup.
Prerequisites
If you want to build and execute the demo code you will need a working WPF dev environment which requires the following: the Microsoft .NET Framework version 3.0 and the Windows Software Development Kit (SDK), Visual Studio 2005 (C# Express ok), Visual Studio 2005 extensions for .NET Framework 3.0 (WCF & WPF, November 2006 CTP or newer), and Microsoft Expression Blend (RC Version or greater).
First let’s play with a trivially simple WPF project. Source code here.
Step 1
We start Start with an empty WPF project in VS2005 which I’ve named WPFDemo.
In Solution Explorer, click the Show All Files button.
Select the files: (all the code files in the Step 1 folder)
App.xaml
ExpenseReportPage.xaml
ExpenseReportPage.xaml.cs
HomePage.xaml
HomePage.xaml.cs
Right-click on them and Include In Project.
Look at App.xaml:
1 <Application
2 xmlns=“http://schemas.microsoft.com/winfx/2006/xaml/presentation“
3 StartupUri=“HomePage.xaml“>
4 </Application>
App.xaml declares the application starting point. So let’s try to build. Assuming you followed the steps exactly you will see the following build error:
WPFDemo.exe does not contain a static ‘Main’ method suitable for an entry point
This is because by default when App.xaml was included by Visual Studio its Build Action was set to Page.
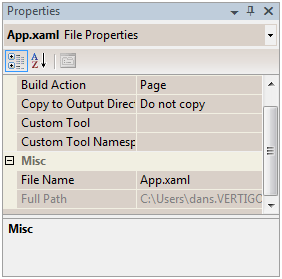
Select App.xaml and change its Build Action to Application Definition. Confirm that the application now builds and runs correctly.
Note: App.xaml is the most common name for this file but there’s nothing special about the name App.xaml. What’s important is its content and that it is configured as the Application Definition. Since the error message we got above implies this configuration has something to do with the Main() method it should also make sense that an application can only have one file configured as the application Definition.
In the steps above I’ve enacted discussion that may be found on pp. 479-481 of Petzold’s Applications = Code + Markup.
Where’s Main()?
After a quick examination of all the files we included in the project so far you should be asking about Main() – like, where is it? App.xaml defines the entry point to the application and if you dig into the generated files for the application you will find an App.g.cs file in the obj\Debug folder:
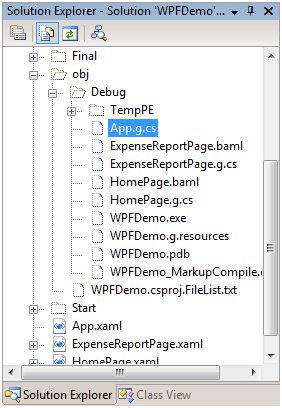
Examining this file we find a Main():
33 /// <summary>
34 /// GeneratedApplication
35 /// </summary>
36 public partial class GeneratedApplication : System.Windows.Application {
37
38 /// <summary>
39 /// InitializeComponent
40 /// </summary>
41 [System.Diagnostics.DebuggerNonUserCodeAttribute()]
42 public void InitializeComponent() {
43
44 #line 3 “..\..\App.xaml”
45 this.StartupUri = new System.Uri(“HomePage.xaml”, System.UriKind.Relative);
46
47 #line default
48 #line hidden
49 }
50
51 /// <summary>
52 /// Application Entry Point.
53 /// </summary>
54 [System.STAThreadAttribute()]
55 [System.Diagnostics.DebuggerNonUserCodeAttribute()]
56 public static void Main() {
57 XamlGeneratedNamespace.GeneratedApplication app = new XamlGeneratedNamespace.GeneratedApplication();
58 app.InitializeComponent();
59 app.Run();
60 }
61 }
The #line 3 directive causes any compile error occurring here to be directed to the file indicated: back to the XAML file. The #line default, #line hidden directives restore error indication back to normal. These directives also affect debug step-through.
The key takeaways from this example are:
- VS2005 creates all kinds of generated files you should be aware of.
- Even a “pure XAML” app involves additional generated code and files.
- VS2005 patched for WTF is not (yet) fully XAML aware.
Obviously it would be great if we could wait for the next release of Visual Studio codenamed “Orcas” (Here’s a great site by Scott Guthrie all about Orcas). But here at Vertigo we’re delivering WTF applications today so we need to be aware of the issues – and build anyway.
I’ll jump ahead by simply pasting in more UI content to the application and demonstrate a typical but very simple Blend/VS2005 development scenario. Source code here.
Step 2
Without making any changes to the structure of the app but adding UI code we get:
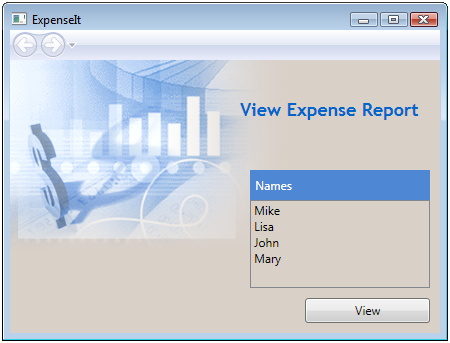
The idea is that you select a name on the list and click the button to view that person’s expense report. If you’re curious: the data displayed is hard coded as XML structured data in the HomePage.xaml file.
The first thing to do is to name the Button element in the HomePage.xaml file. To me it’s interesting that we already built and ran this app and yet nothing squawked about the button being an un-named element.
Being a Visual Studio-centric kind of guy I naively click on the button in the Design view and look at the control properties.
First I look for the “Name” property. Huh, not there.
Ok, next I look for the “ID” property. Double-Huh, that’s not there either?
To name the button you need to go to the XAML code and in the tag <Button add Name=“btnView“. Note that there is Intellisense support within the XAML code an the Button tag.
Now I want to wire the Click event.
Can I access control events in the Properties panel? No.
Can I double-click on the button in the design view to add a click handler? No.
However, I can add a reference to the “Click” property in the Button tag but this does not automagically wire up an event handler stub.
What I can do is this: rebuild the app (not just Build but Rebuild) so that the Name I gave the button is in-scope for Intellisense and then add the handler in the XAML file’s associated .cs file.
In HomePage.xaml.cs, I add the event handler by starting to type “btn…” whereupon Intellisense shows me the btnView and I add the event handler and let VS2005 create an event handler stub.
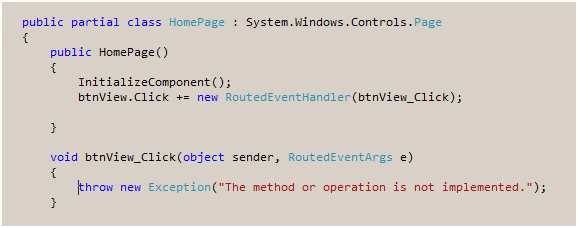
All looks ok – and utterly familiar. I then edit the handler to call goToExpenseReportPage() which I have already prepared and the application is finished.
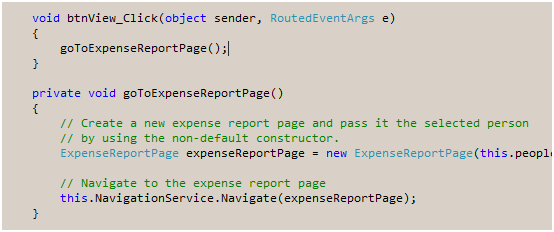
Now let’s add a twist. Go to the event handler and select the btnView_Click name and select Refactor / Rename and rename the event handler any other random name. I used ShowExpenseReport. Rebuild the code and confirm the application still works correctly.
Mixing it up with Blend
Now open the same solution in Blend.
Select the button in the design view and select the events list in the properties panel.
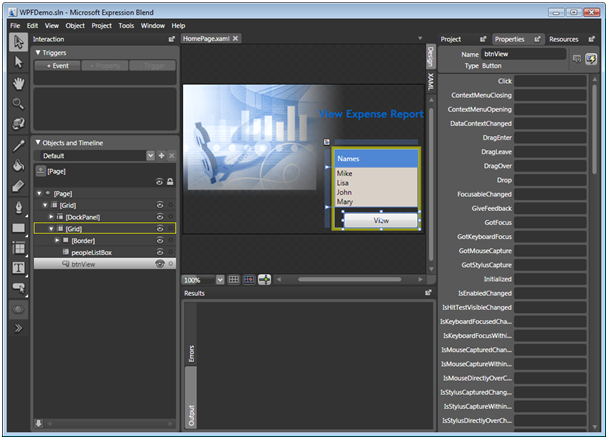
Note: from Blend’s perspective the button’s click event is not wired up. This is because Blend manipulates the application by only looking at a project’s XAML files, not its .cs files. Therefore, it is excruciatingly easy at this point to go ahead and wire the click event up AGAIN.
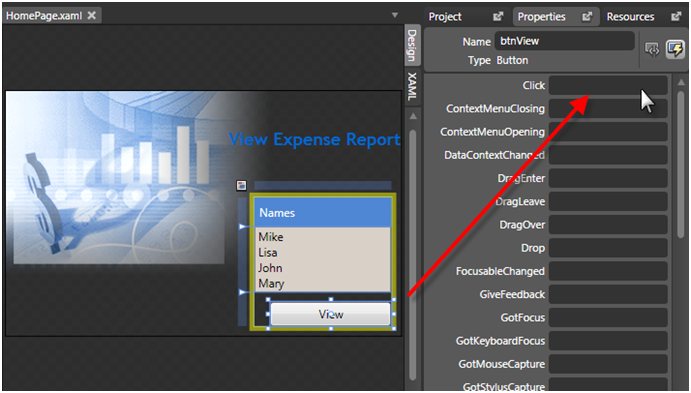
Just to make a point, let’s do just that. let’s wire up a second event handler to the button.
In Blend double-clicking in the click event box shown above wires up the event and creates the event handler stub in HomePage.xaml.cs. This sequence should open and/or foreground VS2005 to the created stub. We can add a call to goToExpenseReportPage() and the code builds fine but may, or may not, run fine. On some machines the second event handler fails when called because navigation has already moved to the second page, disposing of objects needed by the handler code so you get null reference errors.
If we examine HomePage.xaml.cs we note that it still only shows the first event handler wired that we created with VS and does not show the connection to the second Blend created handler.
If we examine the XAML file we find the button tag has a reference to the Blend created handler (Click=“btnView_Click“/>) but no reference to the VS created handler. T add more confusion, the VS takes the Blend created event handler reference and generates the expected hookup in the generated file obj\Debug\HomePage.g.cs:
#line 81 “..\..\HomePage.xaml”
this.btnView.Click += new System.Windows.RoutedEventHandler(this.btnView_Click);
Again the #line directive redirects debug and error output.
Given that we’re building our apps with a combination of Visual Studio and Blend what should we do?
Blend/VS2005 recommendations:
- Use Blend to wire the events and create stubs. This means the event will be seen in the element’s tag in the XAML.
- Use the default name for the event handler.
Number 1 implies that a typical WPF app will have events and handlers referenced to controls in the XAML file, the handlers in the code-behind file, and actual code wire-ups of the events in the generated .cs files (the code-behind-behind files).
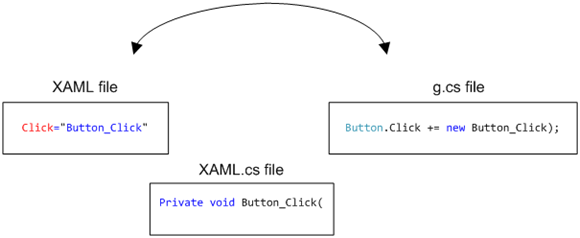
If you look purely at the code behind file (XAML.cs above) you are going to see the handlers with nothing more than their names to hint which control they bear on.
This is why I say (Number 2) renaming event handlers away from the default [control name]_[event name] pattern is a bad idea.
Why emphasize and favor using Blend? Currently Blend behaves in design mode the way we wish Visual Studio would. I’m sure this will all have to be revisited once Orcas ships but for now this is the approach I recommend.
XAML in WPF
At the beginning I made some claims that I would discuss XAML’s role from a more architectural point of view.
In architecture docs at MSDN I found two statements that seem to bear on this:

If you work the first half of Petzold’s Applications = Code + Markup, that is, the non-XAML part, you find that making a WPF is properties, properties, properties. Set the 85 bagillion properties of a Window, of a button, etc.
But look at it this way: properties are data. Data can be easily described by XML. Enter XAML. Once you have all the properties in your applications held in XAML it becomes really easy for any number of tools to traverse and modify this data.
We just demonstrated this by using Blend and Visual Studio to act on the same XAML files. The process is not perfect yet but it is a powerful technique I think we will see more and more often.